

No Language Left Behind
What is NLLB?
In July 2022, FAIR (Facebook AI Research) released a large multilingual transformer model that they call No Language Left Behind, or NLLB for short. This model builds on the work the FAIR team did for their submissions to the WMT machine translation competitions to train a state-of-the-art crosslingual model for 200 languages. The training protocol combines the best practices that FAIR uncovered in the last 5 years to produce a model that yields >30 BLEU for almost all the low resource languages included in it. One of these languages is standard Tibetan.
For more detail, see FAIR's blog post on NLLB at https://ai.facebook.com/blog/nllb-200-high-quality-machine-translation/ as well as their paper at https://arxiv.org/abs/2207.04672.
Can we use NLLB directly, without any training?
Simply, no. Consider some example sections from the Diamond Cutter Sutra.
| Tibetan | SOTA translation | Zero-shot NLLB translation |
|---|---|---|
| །འདི་སྐད་བདག་གིས་ཐོས་པ་དུས་གཅིག་ན། | Thus did I hear at one time. | And I heard a voice in my ear, and it came to pass, |
| དེ་ནས་བཅོམ་ལྡན་འདས་སྔ་དྲོའི་དུས་ཀྱི་ཚེ་ཤམ་ཐབས་དང་ཆོས་གོས་བགོས་ཏེ། ལྷུང་བཟེད་བསྣམས་ནས། མཉན་ཡོད་ཀྱི་གྲོང་ཁྱེར་ཆེན་པོར་བསོད་སྙོམས་ཀྱི་ཕྱིར་ཞུགས་སོ། | Early one morning, the Blessed One donned his lower garment and Dharma robes, and, carrying his alms bowl, he went for alms in the city of Sravasti. | And he took his clothes, and his clothes, and his clothes, [repeating forever...] |
| །གཟུགས་ལའང་མི་གནས་པར་སྦྱིན་པ་སྦྱིན་ནོ། | They practice generosity without abiding in physical forms. | And he hath given his soul, and hath given his soul, and hath not kept his body. |
We will stop here, as the situation really does not improve in any of the other texts. Since the results are almost completely unrelated to the "true" translations, we do not bother spending any time tweaking various generation parameters, such as repetition penalties and so forth.
Of note is the clear indication of the NLLB training data - it appears to have identified that we are in a religious corpus and is attempting to regurgitate passages from the New Testament. We will return to this in a later blog post when we discuss augmentation with NLLB data.
Neural architecture and tractability
The full NLLB model uses a sparsely gated mixture-of-experts neural architecture that results in ~54 billion parameters. Thankfully, to make the model tractable FAIR released multiple dense distillations of NLLB. The architecture of the dense distillations is basically that of BART: it utilizes sinusoidal positional embeddings, dense attention layers with encoder cross-attention in the decoder, and two feature transformer layers in each transformer block. The smallest dense distillation is ~600 million parameters, at a cost of ~4 BLEU points on Facebook's FLORES-200 test set. Since the larger models are, for any practical purpose, intractable on modern hardware that would be available to typical users, we will focus on the ~600 million parameter dense distillation, which we will refer to by its Hugging Face name as NLLB-200-distilled-600M, or simply NLLB for short.
Even with Facebook's dense distillation, NLLB-200-distilled-600M still consumes a large amount of VRAM during training. A 16GB GPU, such as the V100s and A100s available on typical cloud services, only accomodates a batch size of 1, resulting in very slow and expensive fine-tuning.
However, if we are fine-tuning the model on a single language pair, the vast majority of the tokens never appear in our dataset. This means that their token embeddings are never updated by the back-propagation. Yet the embeddings for these tokens are loaded into GPU memory, wasting precious VRAM. We implement a simple token restriction trick: we remove the embeddings of tokens we will never use during training from the non-contextual embedding layer at the top of the transformer, as well as from the language modeling head at the bottom of the transformer. This reduces the number of parameters by almost 2x. The improvement in the backprop VRAM usage is quadratic, enabling us to use a batch size of ~4 on readibly available hardware without the need for expensive and brittle clustering.
The only potential performance cost of this strategy is in the removal of the parameters from the language modeling head. One simple way to avoid any performance cost to the token restriction trick is to freeze this LM head - this is precisely what happens to the parameters of the LM head that correspond to tokens that aren't included in the restriction. To estimate the impact of token restriction, we compare the validation set cross-entropy of fine-tuned NLLB-200-distilled-600M with and without freezing the LM head, see figure 1. As we can see, there is some small impact. Keep in mind however, that in our token restriction trick, the tokens that are dropped are not present in the dataset at all. SGD with the cross-entropy loss will push their probability to zero. Freezing their parameters by dropping them from the training is likely preferable to allowing them to converge to zero. What this really tells us is that a more diverse dataset is better.
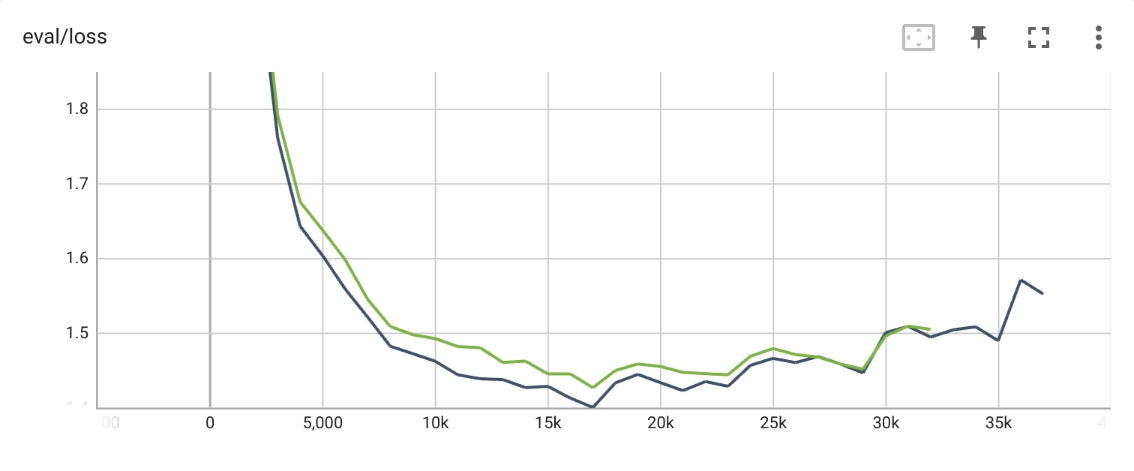
Figure 1: Training curves for olive-cormorant-NLLB (see below) with and without freezing the LM head - validation cross-entropy
- ▩ Frozen LM head
- ▩ Unfrozen LM head
It is likely that combining token restrictions with distillation would result in models that are deeper than NLLB-200-distilled-600M but still have a relatively small number of parameters. While this, of course, removes most of the languages other than the ones we are interested in, the transfer learning from those languages that occured during the training of NLLB is preserved. Such models are likely to be better, however, their improvement should be capped by the ~4 BLEU that was lost in the distillation process. We may investigate this in the future.
Modularity - mixing and matching encoders and decoders
The NLLB model is a standard encoder-decoder stack. We would like to preserve this encoder-decoder structure but there is no a priori reason not to mix and match encoders and decoders. The advantage of retaining the NLLB encoder is that the decoder is already adapted to it - the training will start further along the learning curve. However, our own olive-cormorant pre-trained encoder has a number of advantages as well:
- Olive-cormorant uses the olive-big tokenizer. This tokenizer is guaranteed to have no UNKs on Tibetan text. The NLLB tokenizer has ~3% UNK rate on the Kangyur and Tengyur; this is not huge but it is not zero.
- We pre-trained olive-cormorant on the Kangyur and Tengyur, this encoder may be more in-domain.
- Olive-cormorant is based on AlBERT, thus it has substantially fewer parameters than the NLLB encoder (~101 million) and is much faster and more memory efficient in inference.
With this in mind, we compare three models:
- Olive-cormorant-BART: The olive-cormorant encoder and the BART decoder, both pre-trained by their respective authors.
- Olive-cormorant-NLLB: The olive-cormorant encoder and the NLLB decoder (with token restriction to English), both pre-trained by their respective authors.
- NLLB: NLLB-200-distilled-600M with token restriction to Tibetan on the encoder side and English on the decoder side.
Without pooled context injection
We begin with a direct comparison of the encoder-decoder stacks without any context injection. The training curves are in figure 2.
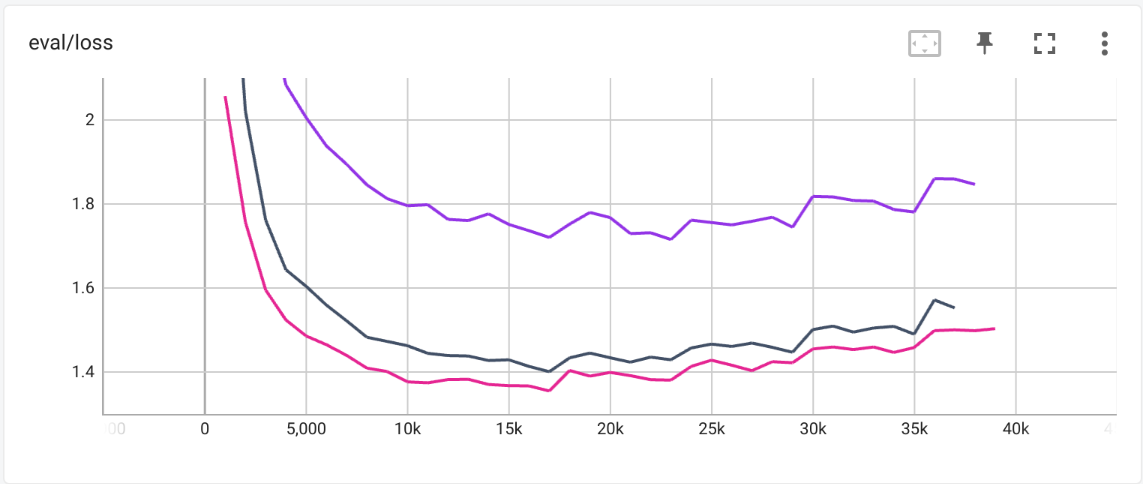
Figure 2: Training curves for three models without context injection - validation cross-entropy
- ▩ Olive-cormorant-BART
- ▩ Olive-cormorant-NLLB
- ▩ NLLB
As we can see, the gain from the NLLB decoder is large, while the gain from the NLLB encoder is smaller. Note that this result is generally consistent with prior experience of people working with encoder-decoder models. This result also begs the question of what the difference between olive-cormorant-NLLB and NLLB is on test translations when evaluated by a human. We will investigate this question after comparing the models with context injection.
With pooled context injection
We use our champion context injection methodology - BART-base context encoding with an additional attention layer on top, followed by BOS token pooling and injection into a second language identification token embedding in the decoder, see our earlier work on context injection. The training curves are in figure 3.

Figure 3: Training curves for three models with context injection - validation cross-entropy
- ▩ Olive-cormorant-BART, no context
- ▩ Olive-cormorant-BART, with context
- ▩ Olive-cormorant-NLLB, with context
- ▩ NLLB, with context
In figure 4 we compare the performance of the two NLLB models with and without context injection.
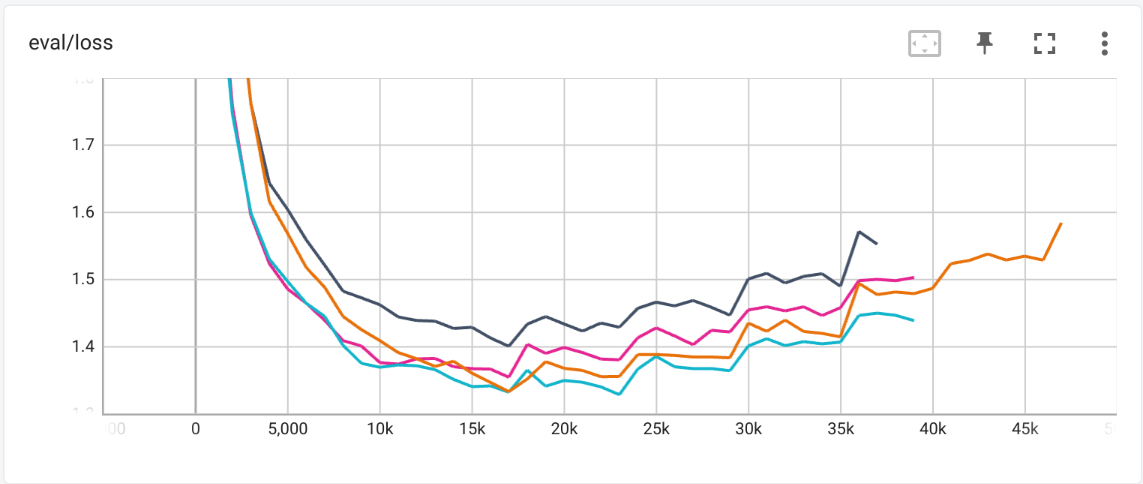
Figure 4: Training curves for models involving NLLB with and without context injection - validation cross-entropy
- ▩ Olive-cormorant-NLLB, no context
- ▩ Olive-cormorant-NLLB, with context
- ▩ NLLB, no context
- ▩ NLLB, with context
While NLLB with context has a similar minimum to Olive-cormorant-NLLB with context, this is likely due to noise. The gain from introducing context appears to be slightly larger than the gain from the encoder. These numbers are consistent with our earlier findings.
Human evaluation
Olive-cormorant-NLLB with and without context
We begin by translating our test document suite with olive-cormorant-NLLB with and without context, and visually inspect the results.
- Without context: Diamond Cutter Sutra, Madhyamakavatara, Manjusrinamasamgiti.
- With context: Diamond Cutter Sutra, Madhyamakavatara, Manjusrinamasamgiti.
The Diamond Cutter doesn't seem to benefit much from context injection. This is not surprising, since it is a relatively well-formed text that is quite close to the training data. The Madhyamakavatara is more difficult since it is poetry and is further from the training data. We do notice less pronoun switching with context injection. For example:
| Tibetan | Without context | With context |
|---|---|---|
| །།ཤེས་བྱའི་བུད་ཤིང་མ་ལུས་སྲེག་པའི་མེའི། །འོད་འབྱུང་ཕྱིར་ན་ས་ནི་གསུམ་པ་འདི། | this third earth is illuminated by the light of the fire that burns all the sticks of knowledge. | this third earth is filled with the light of the fire that burns away all the sticks of knowledge. |
| །འོད་བྱེད་པ་སྟེ་བདེ་གཤེགས་སྲས་པོ་ལ། །དེ་ཚེ་ཉི་ལྟར་ཟངས་འདྲའི་སྣང་བ་འབྱུང་། | the sun-like radiant son of the sugatas will at that time shine like copper. | illuminating, the son of the blissful one shines like the sun. |
| །གལ་ཏེ་གནས་མིན་འཁྲུག་པ་འགའ་ཡིས་དེའི། །ལུས་ལས་ཤ་ནི་རུས་བཅས་ཡུན་རིང་དུ། །སྲང་རེ་རེ་ནས་བཅད་པར་གྱུར་ཀྱང་དེའི། །བཟོད་པ་གཅོད་པར་བྱེད་ལ་ལྷག་པར་སྐྱེ། | even if the body, with its flesh and bones, were severed over a long period of time by some non-dwelling or disturbed person, their patience would be utterly restrained. | if he were to cut off his flesh, along with his sinews and veins, from his body over a long period of time, then his patience would diminish and he would be reborn again. |
| །བདག་མེད་མཐོང་བའི་བྱང་ཆུབ་སེམས་དཔའ་ལ། །གང་ཞིག་གང་གིས་གང་ཚེ་ཇི་ལྟར་གཅོད། །གང་ཕྱིར་ཆོས་ཀྱང་དེ་ཡིས་གཟུགས་བརྙན་ལྟར། །མཐོང་བ་དེས་ཀྱང་དེ་ཡིས་བཟོད་པར་འགྱུར། | those bodhisattvas who see selflessness will be patient when they see the dharma as if it were a reflection. | whoever disrupts the bodhisattvas who see selflessness, and sees that phenomena are like reflections, will be able to endure them. |
| །གནོད་པ་བྱས་པས་གལ་ཏེ་དེར་བཀོན་ན། །དེ་ལ་བཀོན་པས་བྱས་ཟིན་ལྡོག་གམ་ཅི། | if someone tries to harm you, how can you stop what you have done? | if he is being led astray by those who have done harm to him, how could he be prevented from doing so? |
| །དེ་ཕྱིར་དེར་བཀོན་ངེས་པར་འདིར་དོན་མེད། | therefore, there is nothing to be found here. | that being the case, there is surely no benefit here. |
| །འཇིག་རྟེན་ཕ་རོལ་དང་ནི་འགལ་བར་འགྱུར། | they will fall away from the next life. | he will face a transgression in the afterlife. |
| །སྔོན་བྱས་པ་ཡི་མི་དགེའི་ལས་ཀྱི་འབྲས་བུ་གང་། །ཟད་པར་བྱེད་པར་བརྗོད་པར་འདོད་པ་དེ་ཉིད་ཀོ། | the fruition of unvirtuous actions that i have previously created is precisely what i wish to expunge. | he wishes to utter the words that bring an end to the results of nonvirtuous actions he committed in the past. |
| །གཞན་ལ་གནོད་པ་དང་ནི་ཁྲོ་བས་སྡུག་བསྔལ་ཕྱིར། །ས་བོན་ཉིད་དུ་ཇི་ལྟ་བུར་ན་འཁྲིད་པར་བྱེད། | for the sake of others harm and anger, how does it lead to a seed? | because he is suffering from harm and anger toward others, how can he be a seed? |
| །གང་ཕྱིར་རྒྱལ་སྲས་རྣམས་ལ་ཁྲོས་པ་ཡིས། །སྦྱིན་དང་ཁྲིམས་བྱུང་དགེ་བ་བསྐལ་པ་བརྒྱར། །བསགས་པ་སྐད་ཅིག་གིས་འཇོམས་དེ་ཡི་ཕྱིར། །མི་བཟོད་ལས་གཞན་སྡིག་པ་ཡོད་མ་ཡིན། | because the generosity and discipline that arise from anger toward the sons of the victorious ones, which have been accumulated over a hundred eons, are instantaneously destroyed, there is no other non-dharma than patience. | because he is angry with the sons of the victorious ones and destroys the accumulation of virtue arising from generosity and discipline for a hundred eons, there is no other sin than patience. |
This clearly illustrates the difference between context injection and not. The context-injected model is more consistent and fluent, even at the cost of repeating pronouns and other context indicators. This is particularly visible in the Manjusrinamasamgiti:
| Tibetan | Without context | With context |
|---|---|---|
| སྦྱིན་བདག་ཆེན་པོ་གཙོ་བོ་སྟེ། །ཚུལ་ཁྲིམས་ཆེན་པོ་འཆང་བའི་མཆོག །བཟོད་ཆེན་འཆང་བ་བརྟན་པ་པོ། །བརྩོན་འགྲུས་ཆེན་པོ་བརྟུལ་བ་ཡིན། ། | the great benefactor, the foremost holder of the great discipline, the steadfast holder of great patience, the one with great diligence and determination, | it is supreme, the great benefactor. it is the supreme holder of great discipline. it possesses great patience and is steadfast, with great diligence and self-control. |
| བསམ་གཏན་ཆེན་པོ་ཏིང་འཛིན་གནས། །ཤེས་རབ་ཆེན་པོའི་ལུས་འཆང་བ། །སྟོབས་པོ་ཆེ་ལ་ཐབས་ཆེ་བ། །སྨོན་ལམ་ཡེ་ཤེས་རྒྱ་མཚོ་སྟེ། ། | they maintain the absorption of great concentration and possess the body of great insight. they possess great strength and great skill. they have the ocean of aspiration and wisdom. | it is endowed with great concentration and absorption. it has the body of great insight. it possesses great strength and great skill. it is the ocean of aspiration and wisdom. |
| བྱམས་ཆེན་རང་བཞིན་དཔག་ཏུ་མེད། །སྙིང་རྗེ་ཆེན་པོ་བློ་ཡི་མཆོག །ཤེས་རབ་ཆེན་པོ་བློ་ ཆེན་ལྡན། །མཁས་པ་ཆེན་པོ་ཐབས་ཆེ་བ། ། | he has an immeasurable nature, great love, great compassion, supreme intelligence, great wisdom, great skill, and great skillful means. | it is the immeasurable nature of great loving kindness. it is endowed with great compassion and supreme intellect. it possesses great wisdom and great skillful means. |
| ... | ... | ... |
| ཐོག་མ་མེད་པ་སྤྲོས་མེད་བདག །དེ་བཞིན་ཉིད་བདག་དག་པའི་བདག །བདེན་པར་སྨྲ་ཞིང་ཚིག་མི་འགྱུར། །ཇི་སྐད་སྨྲས་པ་དེ་བཞིན་བྱེད། ། | he is the self without beginning, the self free from elaboration, the true self, and the self of purity. he speaks the truth, does not change words, and acts according to what he has said. | he is the self without beginning and without conceptualization, the self of reality. he is a pure self. he speaks truthfully and does not change his words. he fulfills what he preaches. |
| གཉིས་སུ་མེད་དང་གཉིས་མེད་སྟོན། །ཡང་དག་མཐའ་ལ་རྣམ་པར་གནས། །བདག་མེད་སེང་གེའི་སྒྲ་དང་ལྡན། །མུ་སྟེགས་རི་དྭགས་ངན་འཇིགས་བྱེད། ། | they teach the absence of duality and nonduality. they are established in the limit of reality. they possess the lions roar of selflessness. they frighten the tirthikas and the evil spirits. | he teaches nonduality and non-duality, abides in the limit of reality, and is endowed with the lions roar of selflessness. he is the fearful fox of the tirthikas. |
| ཀུན་ཏུ་འགྲོ་བའི་དོན་ཡོད་སྟོབས། །དེ་བཞིན་གཤེགས་པའི་ཡིད་ལྟར་མགྱོགས། །རྒྱལ་བ་དགྲ་རྒྱལ་རྣམ་པར་རྒྱལ། །འཁོར་ལོས་སྒྱུར་བ་སྟོབས་པོ་ཆེ། ། | the powerful cakravartin, the victor, the victorious one, the conqueror, the universal monarch, the meaningful power of all beings, is as swift as the mind of the tathagata. | he is the powerful universal monarch, the unstoppable strength that fulfills the aims of all beings. he is as swift as the mind of the tathagata, the victorious one, the conqueror of enemies, the victor of victory, the great hero. |
The lack of pronoun switching may or may not lead to more correct translations, only more consistent and fluent ones. This is why we expect that online translation is going to be particularly effective. For more details, see our proposal for translator tools.
Olive-cormorant-NLLB versus NLLB
We now translate our test document suite with olive-cormorant-NLLB and NLLB, both trained with context injection, and visually inspect the results.
- Olive-cormorant-NLLB: Diamond Cutter Sutra, Madhyamakavatara, Manjusrinamasamgiti.
- NLLB: Diamond Cutter Sutra, Madhyamakavatara, Manjusrinamasamgiti.
Generally, the difference is smaller. NLLB seems somewhat better at the Diamond Cutter and the Madhyamakavatara. For example, from the Madhyamakavatara:
| Tibetan | Olive-cormorant-NLLB | NLLB |
|---|---|---|
| །འགྲོ་བ་གཡོ་བའི་ཆུ་ཡི་ནང་གི་ཟླ་བ་ལྟར། །གཡོ་དང་རང་བཞིན་ཉིད་ཀྱིས་སྟོང་པར་མཐོང་བ་ཡི། །རྒྱལ་བའི་སྲས་པོ་འདི་ཡི་སེམས་གང་འགྲོ་བ་རྣམས། །རྣམ་པར་གྲོལ་བར་བྱ་ཕྱིར་སྙིང་རྗེའི་དབང་གྱུར་ཞིང་། །ཀུན་ཏུ་བཟང་པོའི་སྨོན་པས་རབ་བསྔོས་དགའ་བ་ལ། །རབ་ཏུ་གནས་པ་དེ་ནི་དང་པོ་ཞེས་བྱའོ། | this mind, the son of the victorious ones, has the power of compassion to liberate beings and is established in joy that is praised by his perfect aspiration. it is like the moon reflected in an unshakable water where all beings are motionless and devoid of intrinsic nature. | for the sake of liberating beings, the minds of these sons of the victorious ones, which are seen to be empty of movement and nature, like the moon reflected in a fluctuating pool of water, become endowed with compassionate faculties and remain joyfully dedicated through the aspirations of samantabhadra. that is what is called the first stage. |
| །དེ་ནས་བཟུང་སྟེ་དེ་ནི་ཐོབ་པར་གྱུར་པ་ཡིས། །བྱང་ཆུབ་སེམས་དཔའ་ཞེས་བྱའི་སྒྲ་ཉིད་ཀྱིས་བསྙད་དོ། | from the time when it is attained, it is said to be a bodhisattva. | from that time onward, he has attained what is described by the term bodhisattva. |
| །འདི་ནི་དེ་བཞིན་གཤེགས་པ་རྣམས་ཀྱི་རིགས་སུའང་སྐྱེས་པ་སྟེ། །འདི་ནི་ཀུན་ཏུ་སྦྱོར་བ་གསུམ་པོ་ཐམས་ཅད་སྤངས་པ་ཡིན། | it is born into the family of the tathagatas. it is the abandonment of all three fetters. | he has been born into the family of the tathagatas. he has abandoned all three fetters. |
On the other hand, olive-cormorant-NLLB seems somewhat better at the Manjusrinamasamgiti. For example:
| Tibetan | Olive-cormorant-NLLB | NLLB | Reference1 |
|---|---|---|---|
| དག་པར་བྱེད་ཅིང་སྡིག་སེལ་བ། །ང་ལས་ཉན་པར་བརྩོན་པ་ནི། །ལེགས་སོ་དཔལ་ལྡན་རྡོ་རྗེ་འཆང་། །ལག་ན་རྡོ་རྗེ་ཁྱོད་ལེགས་སོ། ། | it is good that you should listen to me, o glorious vajra holder, the purifier and dispeller of evil. excellent, vajrapani. | sarvadnivaranadviskamdbhin, it is excellent that you are dedicated to listening to me. excellent, glorious vajradhara, excellent, vajrapani. | Because of that, Overlord of the Hidden, It’s excellent that I’m revealing it to you; |
| གསང་བའི་བདག་པོ་དེ་ཕྱིར་ངས། །ཁྱོད་ལ་ལེགས་པར་བསྟན་པར་བྱ། །ཁྱོད་ནི་རྩེ་གཅིག་ཡིད་གྱིས་ཉོན། །བཅོམ་ལྡན་དེ་ནི་ལེགས་ཞེས་གསོལ། ། | therefore, lord of guhyakas, i will explain this to you. listen, blessed one, with a one-pointed mind. | therefore, lord of the guhyakas, i shall teach you well. listen with one-pointed attention, blessed one, and speak well. | (So) listen with single-pointed mind.” “O Vanquishing Master, that’s excellent,” he replied. |
| ཤིན་ཏུ་རྣམ་པར་དག་པ་ཆེན་་པོ་དབྱིངས་ཀྱི་ཡེ་ཤེས་ལ་ཚིགས་བཅད་ཉི་ཤུ་རྩ་ལྔ། | it is the twenty-fifth verse in the wisdom of the realm of great purity. | in the wisdom of the sphere of great purity, there are twenty-five verses: | Twenty-five Verses, Less a Quarter, on the Deep Awareness of the Totally Pure Sphere of Reality |
| ཕ་རོལ་ཕྱིན་བཅུ་ཐོབ་པ་སྟེ། །ཕ་རོལ་ཕྱིན་པ་བཅུ་ལ་གནས། །ཕ་རོལ་ཕྱིན་བཅུ་དག་པ་སྟེ། །ཕ་རོལ་ཕྱིན་པ་བཅུ་ཡི་ཚུལ། ། | it is the one who has attained the ten transcendences. it is abiding in the ten perfections. there are the ten perfect perfections that are pure. | they have attained the ten perfections, are established in the ten transcendences, are pure, and are in possession of the one hundred perfections. | He has attainment of the ten far-reaching attitudes, Support on the ten far-reaching attitudes, The purity of the ten far-reaching attitudes, The mode of travel of the ten far-reaching attitudes |
We can tentatively say that olive-cormorant-NLLB is slightly better at very specific Buddhist domain text, while the NLLB encoder is better at more general text.
Conclusions and future work
We conclude that the performance gain from the NLLB decoder is large. The gain from the NLLB encoder is smaller and more ambiguous. Unsurprisingly, NLLB still benefits from pooled context injection in much the same way that BART did. We can tentatively hypothesize that the NLLB encoder makes the model slightly better at more standard text, while olive-cormorant-NLLB is slightly better at very specific Buddhist domain text.
It is likely that we may be able to augment the training of olive-cormorant-NLLB with data from the NLLB training dataset. We investigate this in a future blog post. Furthermore, there may be fine-tuning strategies that involve MLM tasks that would allow us to combine the performance of the NLLB and our olive-cormorant encoders. We may investigate this in future work.