

Injecting context during decoding
Ambiguity and context in classical Tibetan
As a written language, Tibetan is a simple language in every way - syntactically, morphologically, and grammatically. The legend is that classical Tibetan was created in the proverbial lab at an ancient Indian Buddhist university. This makes it easy to learn to read classical Tibetan but it also makes it distant from languages more familiar to English speakers, especially the proto-Indo-European languages that are in the Sanskrit tree, including English itself.
One of the ways in which classical Tibetan is different is that, as compared to English, it is highly ambiguous. Pronouns such as he/she/they, prepositions such as among/beside/toward, and even number indicators that indicate whether a noun is singular or plural, are often missing. When these linguistic structures are missing they need to be inferred from the semantic meaning of the preceding text. In the worst case, they cannot be inferred at all and the reader must rely on a verbal explanation by an authentic carrier of the textual tradition.
For an extreme example of this, consider the (in)famous Manjuśrinamasamgiti ("the symphony of the names of Manjushri"). A kind of tantric Heart Sutra, this short esoteric text essentially has three parts:
- Introduction: The assembly is described, Vajrapani asks Śakyamuni to teach and Śakyamuni agrees.
- An uninterrupted chain of hundreds of epithets for Manjuśri as the personification of the qualities of enlightenment.
- The mantra and the rejoicing by the assembly.
The meaning of this text is far out of the scope of what we want to discuss in this short note. Linguistically, the second part of the text consists of hundreds of short sections like this:
ཕྱིར་མི་ལྡོག་པ་ཕྱིར་མི་འོང་།
འཁོར་བའི་ཕ་རོལ་མཐར་སོན་པ།
བདེ་བ་རྙེད་པས་འཇིགས་མེད་ཐོབ།
Consider the first section:
| ཕྱིར་མི་ལྡོག་ | པ་ | ཕྱིར་མི་འོང་ | ། |
|---|---|---|---|
| phyir mi ldog | pa | phyir mi 'ong | shad |
| Never fall back | Personhood indicator (nominalizing particle) |
Never regressing | End of section |
The intended meaning is something along the lines of
He’s irreversible, non-returning, [...] (Berzin, line 51)
where irreversible and non-returning are referring to the state of an Arya Bodhisattva who will never experience any more compulsive Samsaric rebirths and will only be reborn in Samsara by choice and out of compassion.
Linguistically, not only does this section not explain the meaning of irreversible non-returning, it doesn't even contain the pronoun and verb combination he is. It only contains the nominalizing particle pa indicating that it is referring to a being that is irreversible and non-returning, and not the states of being irreversible and non-returning in themselves. While pa defaults to singular male, like in almost all languages, this is only the default. There is no morphological difference between the use of pa to indicate gender versus indicating only that the verb that it is modifying is to be converted to a verbal noun. If the author wanted to explicitly indicate female singular they would have used mo instead. As it stands, we are kept in the dark; this ambiguity is likely deliberate!
We are of the opinion that the Manjuśrinamasamgiti cannot be understood even on the syntactic level without an exogenous explanation of the text. We will also not comment here on the tradition of translating the names of Buddhas and high Bodhisattvas, such as Manjuśri and Śakyamuni, as male (or Tara as female), even though they are all clearly non-gendered. Setting aside these controversies, in order to realize that that the pa should be translated into English with a male pronoun, one has to go back hundreds of sections - all the way to the beginning of the text in which Śakyamuni exclaims that he will give a litany of the names of Manjuśri, and to know that Manjuśri is nominally male.
Implications for machine translation
Neural networks are very powerful but they have many important limitations. One such famous limitation is that neural networks struggle with long range dependecy. While they are excellent at memorizing and combining learned substructures of the training data, these combinations are generally based on nearby data points. Having to look back hundreds of sections to determine the implied gender of a noun is a tall order even for a human, and neural networks do even worse.
The situation would be difficult even if we could feed the entire text to the encoder. There has been some notable work on long encodings via sparse attention, for example Generating Long Sequences with Sparse Transformers or the more recent LongT5: Efficient Text-To-Text Transformer for Long Sequences. However, for our application we would need to train a model like this on a limited monolingual Tibetan dataset. While we may investigate this eventually, we are sceptical of this approach, at least in its current form. Perhaps some better masking strategy would help here.
Without an extremely long Tibetan encoder, we cannot feed the entire text to the model all at once. This means our translation model has no way to infer the gender of the nouns comprising the epithets of Manjuśri in the Manjuśrinamasamgiti at all.
A simpler version of the problem would be to ask for continuity of pronouns. In other words, instead of accuracy we ask for fluency. Translating line by line produces outputs like this:
གཅིག་པུ་སྲ་མཁྲེགས་རྗོ་རྗེའི་བདག །སྐྱེས་མ་ཐག་ཏུ་འགྲོ་བའི་བདག །ནམ་མཁའ་ལས་བྱུང་རང་བྱུང་བ། །ཤེས་རབ་ཡེ་ཤེས་མེ་བོ་ཆེ། །
he is solid, solid, and compassionate. as soon as he is born, he is the lord of beings. he is self-arisen, the great fire of wisdom, arisen from the sky.
འོད་ཆེན་རྣམ་པར་སྣང་བར་བྱེད། །ཡེ་ཤེས་སྣང་བ་ལམ་མེ་བ། །འགྲོ་བའི་མར་མེ་ཡེ་ཤེས་ སྒྲོན། །གཟི་བརྗིད་ཆེན་པོ་འོད་གསལ་བ། །
it is a great light, a shining light, and a brilliant light. it is the lamp for beings, the lamp of wisdom, and the light of great splendor.
[...]
རྡོ་རྗེ་ལས་སྐྱེས་རྡོ་རྗེའི་བདག །རྡོ་རྗེ་སྙིང་པོ་མཁའ་འདྲ་བ། །མི་གཡོ་རལ་བ་གཅིག་གིས་བསྒྱིངས། །གླང་ཆེན་ཀོ་རློན་གོས་སུ་གྱོན། །
arajaprabha is born from the vajra and is like space. he wears a single shawl on his head and is wearing an elephant-tail whisk.
གྲགས་ཆེན་ཧཱའ་ཧཱ་ཞེས་སྒྲོགས་པ། །ཧཱི་ཧཱི་ཞེས་སྒྲོག་འཇིགས་པར་བྱེད། །གད་མོ་ཆེན་མོ་གད་རྒྱངས་ཅན། །རྡོ་རྗེ་གད་མོ་ཆེར་སྒྲོགས་པ། །
they cried out, hum phat. they terrorized him with cries of ha ha. they cried out loudly and roared with the thunder of the vajra.
རྡོ་རྗེ་སེམས་དཔའ་སེམས་དཔའ་ཆེ། །རྡོ་རྗེ་རྒྱལ་པོ་བདེ་བ་ཆེ། །རྡོ་རྗེ་དྲག་པོ་དགའ་བ་ཆེ། །རྡོ་རྗེ་ཧཱུྃ་སྟེ་ཧཱུྃ་ཞེས་སྒྲོགས། །
vajra is the great being, the great vajra king, great bliss, and great bliss. hum is the hum. this is the sound of hum.
While the ideal model would infer the pronoun "he" everywhere here, this currently requires some new breakthrough technique. A more realistic goal would be to have the decoding produce pronouns that are more consistent:
སངས་རྒྱས་ཐམས་ཅད་བསྐྱེད་པ་པོ། །སངས་རྒྱས་སྲས་པོ་དམ་པའི་མཆོག །ཤེས་པའི་སྲིད་འབྱུང་སྐྱེ་གནས་མེད། །ཆོས་ལས་འབྱུང་བ་སྲིད་པ་སེལ། །
the bodhisattva, the supreme son of the buddha, is the father of all buddhas. he brings the existence of existence to an end. he dispels existence by means of the dharma.
གཅིག་པུ་སྲ་མཁྲེགས་རྗོ་རྗེའི་བདག །སྐྱེས་མ་ཐག་ཏུ་འགྲོ་བའི་བདག །ནམ་མཁའ་ལས་བྱུང་རང་བྱུང་བ། །ཤེས་རབ་ཡེ་ཤེས་མེ་བོ་ཆེ། །
one of a kind, soft-red nature, the lord of beings, born in the sky, the self-arisen one with the great fire of wisdom and wisdom,
[...]
རྡོ་རྗེ་ལས་སྐྱེས་རྡོ་རྗེའི་བདག །རྡོ་རྗེ་སྙིང་པོ་མཁའ་འདྲ་བ། །མི་གཡོ་རལ་བ་གཅིག་གིས་བསྒྱིངས། །གླང་ཆེན་ཀོ་རློན་གོས་སུ་གྱོན། །
vajrasattva, born from the vajra, who is like the sky, wears a single-crested mace on his topknotted hair, and wears silken garments.
གྲགས་ཆེན་ཧཱའ་ཧཱ་ཞེས་སྒྲོགས་པ། །ཧཱི་ཧཱི་ཞེས་སྒྲོག་འཇིགས་པར་བྱེད། །གད་མོ་ཆེན་མོ་གད་རྒྱངས་ཅན། །རྡོ་རྗེ་གད་མོ་ཆེར་སྒྲོགས་པ། །
the one with great renown, the one with the name hrih, the terrifying roar, the great noise, the thundering thunder of the vajra,
རྡོ་རྗེ་སེམས་དཔའ་སེམས་དཔའ་ཆེ། །རྡོ་རྗེ་རྒྱལ་པོ་བདེ་བ་ཆེ། །རྡོ་རྗེ་དྲག་པོ་དགའ་བ་ཆེ། །རྡོ་རྗེ་ཧཱུྃ་སྟེ་ཧཱུྃ་ཞེས་སྒྲོགས། །
bodhisattva mahasattva vajrasattva, great blissful one, great vajra, great joy, hum, phat.
A model like the second example is our goal here.
Note that, in principle, if the contextual semantic consistency were perfect, the model would succesfully extrapolate the pronouns from the beginning of the text. The fact that errors anywhere in the sequence cause it to break the chain of correct decoding is known as error propagation. The reason we would want a very long encoder is to avoid exactly this kind of error propagation problem. In fact, this is one of the main reasons why attention-based models are much better than the old architectures based on cells such as LSTM or GRU. As we pointed out above, unfortunately such models will have problems pre-training on a small dataset like ours. Some breakthrough in the training protocol would be needed.
The two ways to introduce context into the decoding
We tested two different ways to introduce the previous generated English text into the decoding:
- Retrospective decoding: Force the model to regenerate a part of the already-decoded English before translating the next section of inputs.
- Pooled context injection: Introduce an encoder for the previously generated context that is then pooled in some way and the pooled context is injected into the decoding of the next sequence.
The two methods can be combined. We describe each in more detail below.
As an aside, we did not test introducing additional cross-attention layers into the decoder that take encodings of the context as input. This would be essentially a better version of retrospective decoding. Unfortunately, since these are attention layers, they would introduce a large number of new parameters. Due to the small size of our dataset, we are concerned with introducing this many new parameters unless we can pre-train these cross-attention layers in some way. Of course, there is an obvious way to pre-train them using the original BART pre-training scheme by introducing context into the Cloze task. This would be particularly effective if pre-training on highly structured corpora like Wikipedia or books. This may become one of our future experiments.
NB: Both methods are original work from CompassionAI.
Retrospective decoding
This method can be diagrammatically illustrated as follows.
| །ཡང་དེའི་ཚེ་ཚེ་དང་ལྡན་པ་རབ་འབྱོར་འཁོར་དེ་ཉིད་ན་འདུས་པར་གྱུར་ཏེ་འདུག་གོ། | །དེ་ནས་ཚེ་དང་ལྡན་པ་རབ་འབྱོར་སྟན་ལས་ལངས་ཏེ། བླ་གོས་ཕྲག་པ་གཅིག་ཏུ་གཟར་ནས་པུས་མོ་གཡས་པའི་ལྷ་ང་ས་ལ་བཙུགས་ཏེ། | བཅོམ་ལྡན་འདས་ག་ལ་བ་དེ་ལོགས་སུ་ཐལ་མོ་སྦྱར་བ་བཏུད་དེ། བཅོམ་ལྡན་འདས་ལ་འདི་སྐད་ཅེས་གསོལ་ཏོ། | |
|---|---|---|---|
| Beam search 1 | at that time, senior sudbhuti, who was present in the assembly, | ||
| Beam search 2 | at that time, senior sudbhuti, who was present in the assembly, | rose from his seat, draped his shawl over one shoulder, and knelt on his right knee. | |
| Beam search 3 | rose from his seat, draped his shawl over one shoulder, and knelt on his right knee. | joining his palms, he bowed toward the blessed one and said to him, |
- During beam search 1, which in this example is the very first input, the decoding simply generates the result for the input.
- Then, during beam search 2, the model is fed both Tibetan input sections 1 and 2, and the beam search is constrained to first generate the output of beam search 1 (the output in orange). This constraint produces a single beam with the previously generated tokens in it. After generating the previous tokens from beam search 1 (with the CLS token removed), beam search 2 then proceeds unconstrained and generates the rest of the output in green.
- Beam search 3 is similar to beam search 2, except that the tokens of input 1 have fallen out of the lookback window and are no longer part of the constraint.
The algorithm continues in this way until the entire text has been translated.
During training we need long sequences. We use the follows-anywhere sequencing strategy to construct our training dataset.
Pooled context injection
Retrospective decoding retains the sequence structure of the context. An alternative would be to pool the entire previous English into a single embedded representation in some latent space of a fixed dimension. This representation could then be fed to the decoder in some way when decoding the next sentence.
The specific way we inject the context into the decoder is the use a control-like non-contextual token embedding like so:
| [BOS] | [BOS] | at | that | time | , | senior | su | db | h | uti | , | [CLS] |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | CONTEXT EMBEDDING |
415 | 14 | 86 | 6 | 949 | 2628 | 33845 | 298 | 18078 | 6 | 2 |
We introduce two beginning-of-sentence tokens and inject the context into the second one.
If we inject the context embedding into the first [BOS] token we get a model that has much lower cross-entropy on the validation set - in fact, same cross-entropy as the model with two [BOS] tokens - but that cannot generate any text. The beam search fails catastrophically on all examples, producing either empty strings or repeating nonsensical token patterns. This is, of course, due to the importance of the [BOS] token for autoregressive transformer initialization. However, introducing a token in the middle of the target sequence with an out-of-sample embedding has very little impact on the decoding due to the denoising pre-training of BART. We exploit this with the trick of injecting the context into a dummy second token.
To produce the context embedding we tried a number of architectures:
-
DenseFeatureTransformer: encode the context with a frozen pre-trained bidirectional BART encoder, apply one randomly initalized dense layer and sum-pool.
-
BartEncoderLayerOnTop: encode the context with a frozen pre-trained bidirectional BART encoder, apply one more randomly initialized BART encoder layer with attention and feature transformers, and pool by taking the embedding of the first token as in BERT.
-
FullBartEncoder: encode with an unfrozen pre-trained bidirectional BART encoder, and pool by taking the embedding of the first token as in BERT.
Note that this model has >187 million trainable parameters, even when we use only BART-base.
-
BartEncoderFirstLayerOnly: encode with an unfrozen pre-trained bidirectional BART encoder with all but the first encoder layer removed, and pool by taking the embedding of the first token as in BERT.
-
FrozenEmbeddingsWithTwoLayers: encode with an unfrozen pre-trained bidirectional BART encoder with all but the first two encoder layer removed and the non-contextual embeddings frozen, and pool by taking the embedding of the first token as in BERT.
We find that:
- Context injection helps.
- The architecture of the context encoder is less important.
- Deeper encoders are slightly better than shallow, even if frozen. This is likely due to BERTology - semantic encodings are better than syntactic.
See the training curves in the figure below.
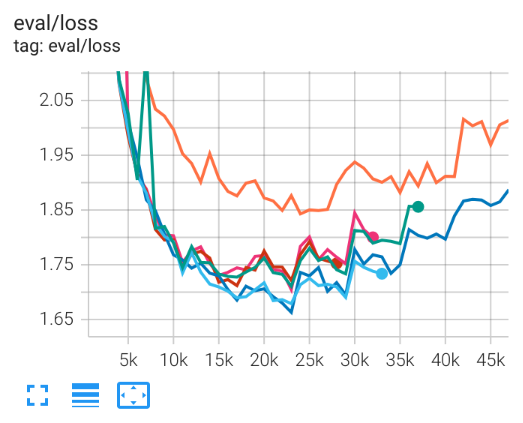
Training curves for different architectures for contextual encoding - validation cross-entropy
The color scheme is:
- ▩: No context injection but with two [BOS] tokens
- ▩: FullBartEncoder
- ▩: FrozenEmbeddingsWithTwoLayers
- ▩: BartEncoderFirstLayerOnly
- ▩: DenseFeatureTransformer
- ▩: BartEncoderLayerOnTop
Results
We find that pooled context injection works quite well. In fact, our sample desired outputs above are outputs from our DenseFeatureTransformer architecture.
We find that retrospective decoding suffers from severe error propagation. When using retrospective decoding, we need fairly long context. However, the constraining in the beam search pushes the resulting sequence far enough off the data manifold that the decoder occasionally produces garbage, such as long strings of Sanskrit-like gibberish or even repeating short token sequences. While this catastrophic failure is rare, it is common enough that the model is rendered unusable for the purpose of translating long texts.
We suspect that self-training may help alleviate this - multiple training runs that include the original training data as well as some of the outputs from the previous trained model. We can attempt to mix model-generated and original translations by using follows-anywhere sequencing. We will report on the results on this blog.